
AI Ecosystem Oversight and Observability
- Oct 1, 2025
- 7 min read
An implementation case study on advancing trust at the application layer

Rather than treating ‘trust in AI’ as a property of foundation models alone, I’m exploring whether it can be advanced mainly at the API and application layer that surrounds them. A simple analogy helps: you don’t need to understand the engine to trust a car; you trust it because the dashboard tells you what’s happening now and the service record shows what happened before. Similarly, while an LLM’s internals remain opaque, we may still reach meaningful auditability, observability, explainability, and user control by instrumenting the parts we own: versioned, user-tunable configurations (models, tools, guardrails), reproducible run contexts, consented data lineage, and agent-to-agent traces with non-human service IDs (agents and tools). For example, if a recommendation engine suggests an action, a trustworthy system would include a clear “reasoning receipt” showing it used your input and history to reach that conclusion.
The open questions are practical: which telemetry is most useful without overwhelming users, how to balance privacy with trace depth, and what minimum schema makes ‘why this action’ explanations credible to auditors and end users? While modern systems use techniques like Retrieval-Augmented Generation (RAG) to show the sources of information, these sources aren't a guarantee of truth. The model's internal reasoning remains a 'black box.'
By instrumenting the application layer with policies-as-code, reproducible runs, and consented data use, we can advance auditability, explainability, and accountability without needing to peek inside the LLM. The aim is not to demystify the model itself, but to standardize transparent practices at the orchestration layer so AI systems become traceable, testable, and ultimately more trustworthy in real-world applications.
Abstract
Trust can be advanced at the application layer around the model. This case study presents four shippable capabilities: pre-deployment and continuous testing, runtime observability and forensics, policies-as-code with user-controlled configuration, and immutable audit trails for human and non-human actors. Drawn from Aedia, a diabetes care companion platform currently under development, the goal is not to provide perfect answers but to ensure traceability, controllability, and consistent behavior that users and auditors can verify.
Who this is for
Application developers, solution designers, and platform engineers building Agentic AI products that must run in production and meet real governance needs.
The simple thesis
There are two layers in production systems.
Foundation models. Powerful but opaque.
APIs and application layer. This is where we have control.
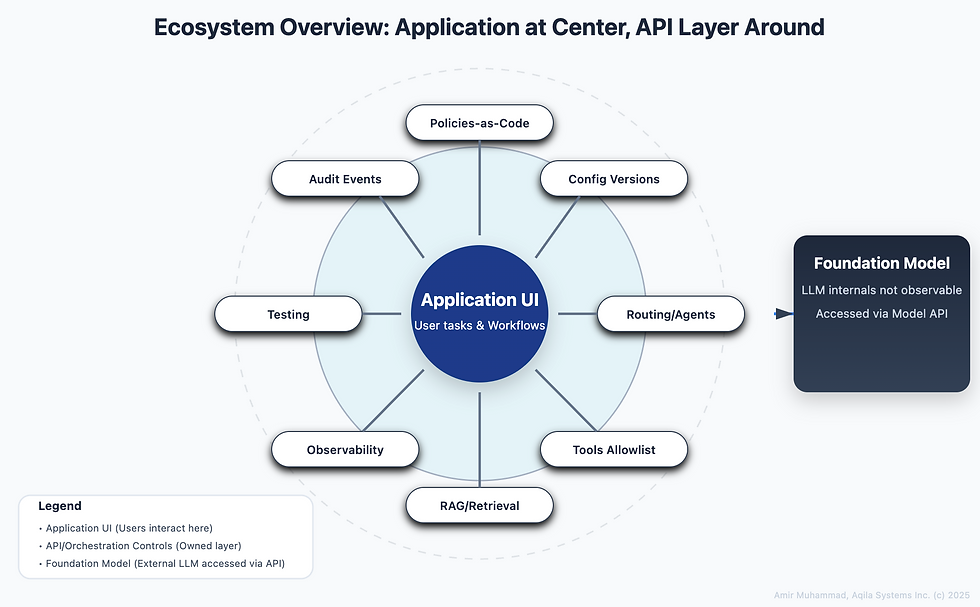
What “trust” means here
First is auditability, where every material action leaves an immutable trail so we can see what happened and when. Second is observability, we can watch runs as they occur and replay them later with the same configuration. Third is explainability, explanations stay grounded in observable facts rather than guesses about hidden model weights. Finally, user control, admins and users can select model profiles, tools, guardrails, and rollout scopes, and those choices are versioned and signed. Together, these pieces make behavior traceable and repeatable without claiming visibility into the model itself.
A four-module operating model

1) Immutable audit and access trails

Record both human and non-human actors. Use service IDs for agents and tools. Keep event signatures and retention policies that match your compliance target.
Minimum audit event schema
{ "event_id": "EVT-9c11",
"timestamp": "2025-09-30T15:04:05Z",
"tenant_id": "TEN-001",
"actor_type": "service",
"actor_id": agent.router",
"action": "tool.call.started",
"resource_type": "run",
"resource_id": "RUN-5FQ",
"inputs_ref": ["PROMPT-abc123"],
"outputs_ref": [],
"policies_ref": ["cite_sources"],
"cost_usd": 0.002,
"status": "in_progress",
"sig": "ed25519:..."
}Enterprise Trust:
In our deployment, configuration control is a super-admin function. Only a small set of authorized roles can create, edit, or roll back configurations, and every change is time-stamped, signed, and attributed to a person or service account. The same audit trail covers test runs and production rollouts, so we can see who changed what and when. We keep a performance history per configuration version to show how each tweak affects latency, safety, and task success. Alerts watch for anomalies in testing and production; if policy violations spike or costs drift, the right people are notified so we can pause or roll back before users feel it.
2) Pre-deployment and continuous testing

Before changes hit users, run scenario packs for safety and performance. Tie tests to the exact configuration version. Keep baselines. Block rollout if thresholds fail.
Minimum test record
{
"test_id": "T-2025-09-30-001",
"config_version": "v15",
"inputs_ref": ["PROMPT-abc123"],
"expected_criteria": {"must_cite": true,
"blocked_terms": ["PHI"]},
"metrics": {"accuracy": 0.82, "latency_ms_p95": 1200, "cost_usd": 0.013},
"result": "pass",
"artifacts_ref": ["ART-789"]
}Validate Before You Trust
Before deployment, we ran predefined scenarios to check that agents behaved safely, reliably, and predictably. We used cases like Daily Management and Insulin Calculation, and we tested each agent on its own, Care Companion, Youth Coach, Education Agent, and Visit Scribe to isolate issues. During each run we measured processing times, routing decisions, and escalation patterns, and we watched the live workflow so we could see messages move through the pipeline. We then reviewed impact: how each agent’s performance affected system outcomes. This made it clear when a change was safe to ship and when it needed more work.
3) Runtime observability and forensics
Show how a request travels through agents and tools. Expose timestamps, costs, source documents, and policy hits. Build a forensics bundle from signed events so anyone can replay the run and verify decisions.
Minimum run context
{
"run_id": "RUN-5FQ",
"parent_run_id": null,
"config_version": "v14",
"model_id": "gpt-x@2025-09",
"prompt_hash": "ph_2c97...",
"retrieval_refs": ["DOC-123", "DOC-987"],
"agent_graph_snapshot": "hash_86aa...",
"consent_token": "CONSENT-ok",
"status": "success"
}
Real-Time Monitoring and Analytics
In operations we watched a small set of signals continuously, then used history to confirm patterns. Live, we looked at orchestrator routing time to see how quickly the system picked the right agent, per-agent execution time to spot slow steps, retrieval latency when RAG was involved, and model response time during inference. We also tracked success rate, confidence, and escalation patterns to understand whether agents were making the right calls.
An interactive network view showed how agents handed off work; each node had a simple status indicator so a failing tool or congested router was easy to spot. When something looked off, we moved to the history panel to drill down by agent and by run, reviewing latency, error rate, policy hits, and cost over time. This combination of live view and historical analysis gave us a clear picture of workflow efficiency and where to tune next.
4) Policies-as-code and user-controlled configuration
Let teams choose models, tools, guardrails, retrieval profiles, and rate limits. Treat configuration as a signed, versioned artifact. Support rollback. Support tenant overrides with approvals.
Minimum config fields
{
"config_id": "CFG-a1b2",
"version": "v15",
"signer": "admin@company.com",
"checksum": "sha256:...",
"model_id": "gpt-x@2025-09",
"tool_allowlist": ["search", "reader"],
"retrieval_profile": "healthcare_default",
"safety_policies": ["no_phi_in_output", "cite_sources"],
"prompt_template_hash": "ph_f3ab...",
"rate_limits": {"rpm": 120},
"cost_ceiling_usd": 50,
"explanation_mode": "concise"
}
Full Control Over Agent Behaviors
We handled behavior through signed configuration versions. For example, moving from v14 to v15 we tightened the tool allowlist, raised the escalation threshold for low-confidence answers, and adjusted tone for youth vs. provider audiences. The change kept system prompts the same but narrowed capabilities and added a clinic-specific compliance preset. In production this reduced unnecessary tool calls, lowered cost per successful task, and kept success rate steady. Because the configuration was versioned and attributed, we could trace exactly which settings produced the behavior and roll back if needed.
How we explain runs in practice
In Aedia we decided to explain only what we can observe. Each run stores the prompt variant used, the tools called, the documents retrieved, the policies enforced, the output, and a simple cost trail. During reviews, we replay the run with the same config to verify the path rather than guessing at the model’s internal reasoning. That boundary kept discussions concrete. Engineers and auditors could point to the same artifacts and reach the same conclusion about “why this action.” The tradeoff is that we do not speculate about the model’s hidden steps. In day-to-day work, that clarity turned out to be more useful than trying to interpret the model itself.
Privacy by default, as implemented
We treated privacy settings as defaults, not checklists. Prompts are hashed at ingestion; full text is stored only when a consent flag is present. Sensitive fields are masked in logs, and instead of saving raw payloads we keep provenance pointers that let us reconstruct the trail when needed. Operationally, we split access: security logs live apart from product analytics, with different roles and retention.
A small set of KPIs that actually help
To keep operations focused, we track a short list of measures. For reliability, we watch p95 end-to-end latency, tool failure rate, and whether escalations happen correctly. For safety, we look at policy violations per 1,000 interactions and results from a small red-team pack. For explainability, we measure how many runs include a complete trace and a usable explanation artifact. For cost, we watch cost per successful task and how that cost changes across configuration versions. For governance, we track the share of configs that are signed and versioned, plus Mean Time To Detect (MTTD) and Mean Time To Respond (MTTR) when anomalies occur.
Notes from implementation in Aedia
Signed events are cheap to emit and very useful later. They make after-action forensics simple.
Small red-team packs catch surprising regressions. Keep them short and run them on every config change.
Config rollouts benefit from approval gates. Treat them like feature flags with audit.
The hardest part is not storage. The hardest part is consistent schemas and discipline. Start small and expand.
Standards alignment at a glance
This approach maps well to existing frameworks. For example, it supports the spirit of NIST AI RMF (govern, map, measure, manage) and ISO-style AI management practices. The goal is not to claim certification here, but to stay compatible with recognized controls and to keep evidence ready for audits.
Limitations and open questions
There are still open points. We are testing how much telemetry is useful before it overwhelms readers. We continue to balance privacy with trace depth, especially in regulated domains. And we see value in a minimal schema that could be shared across vendors so audits do not become custom work every time.
The Path Forward
We cannot see inside the model. That is fine. We can still earn trust by instrumenting what we do control. Test before rollout, observe during runtime, keep policies as code with user control, and record immutable events. When a user asks why the system did something, you should be able to show the exact configuration, the steps, the sources, the policies, and the outcome. That is the path to practical trust.



Comments